Ollama本地部署Deepseek R1

Ollama是一个创新的平台,旨在简化人工智能模型的使用与部署。用户可以轻松地下载、运行和管理各种AI模型,而无需深入的技术背景。Ollama提供了友好的用户界面,使得开发者和研究人员能够快速实现他们的想法,并将AI应用于实际项目中。无论是文本生成、图像处理还是其他机器学习任务,Ollama都能提供高效的解决方案,助力用户在AI领域的探索与实践。

无需多言,2025-01-20 Deepseek开源R1模型,以低成本获得对标o1的性能,最重要是 开源, 开源, 开源!
由于准备在主力机Windows上运行大模型的显卡,以下介绍Windows的安装方案。实际上,各个安装方案差距很小,Ollama也支持Docker部署,几乎实现了傻瓜式操作。
🛠️ 安装并运行Ollama
访问Ollama官网下载对应系统的安装包。
⚠️ 注意:Windows的安装包一点击就立刻自动安装到C盘,无法修改路径。
安装完成后,安装窗口会自动消失,可能会让人怀疑是否安装成功。不过可以在Windows开始菜单的最近安装项目中找到Ollama。

点击运行Ollama,经过短暂的加载后不会有什么反应,没有交互界面,但在右下角托盘中可以看到Ollama的图标。
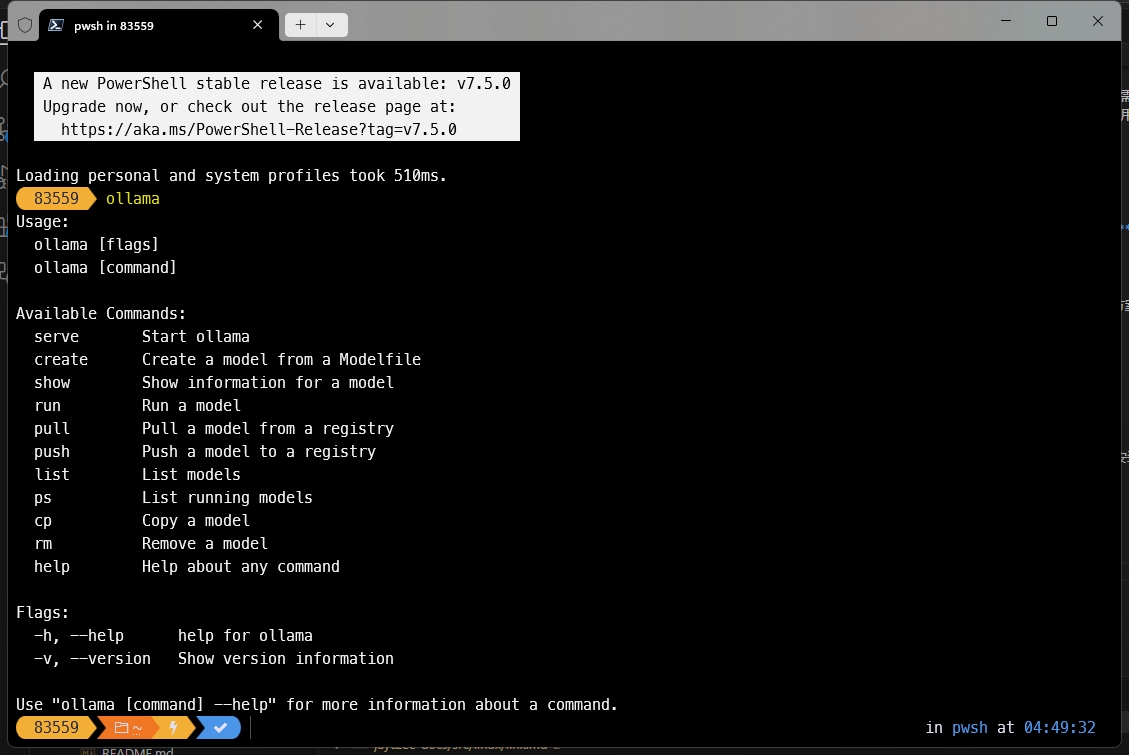
此时打开cmd,输入ollama,若输出help相关信息则证明已安装成功。
📥 下载并运行Deepseek R1模型
访问Ollama Models列表,搜索Deepseek R1模型,并访问详情页。
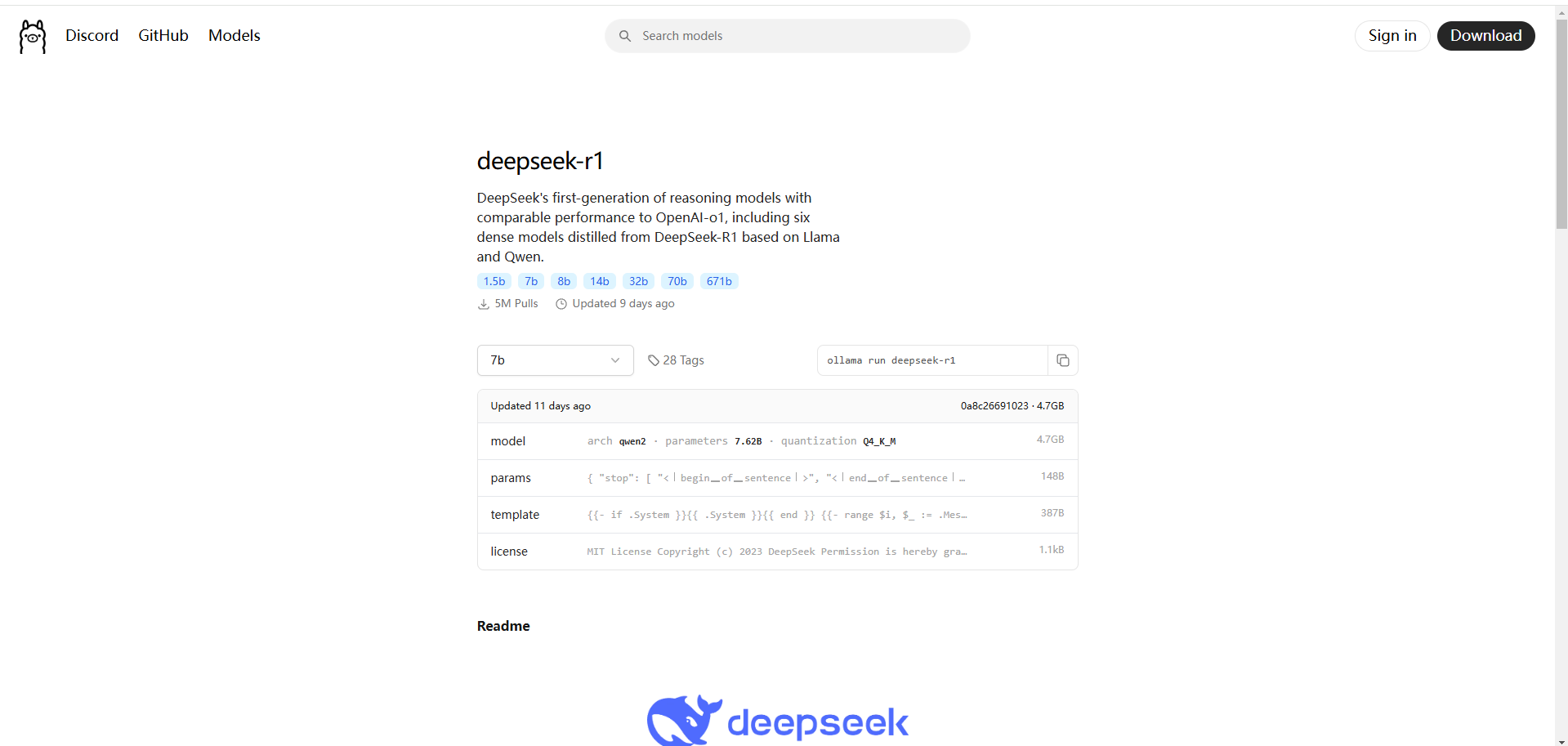
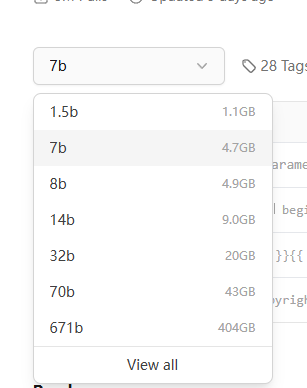
在下方tags中可以看到模型不同params大小的版本以及所需的显存(或内存)大小。
注意
注意:Deepseek R1实际上并没有14b的版本,只有671b的原版。tags中显示的7b、8b等其他版本均为通过Qwen模型进行提炼的更小版本。
提示
大模型在推理时,会将参数(param)加载到显存或内存中。如果计算机配备了高性能显卡进行推理,将参数加载到显存中比加载到内存中进行推理要更快。
我的显卡是 RTX 4070 SUPER,配备 12GB 显存,因此选择 14b 的版本进行下载。回到CMD,在CMD中运行如下命令,随后Ollama将开始下载对应的模型:
ollama pull deepseek-r1:14b
根据控制台打印的信息,使用 ollama run 命令运行模型:
ollama run deepseek-r1:14b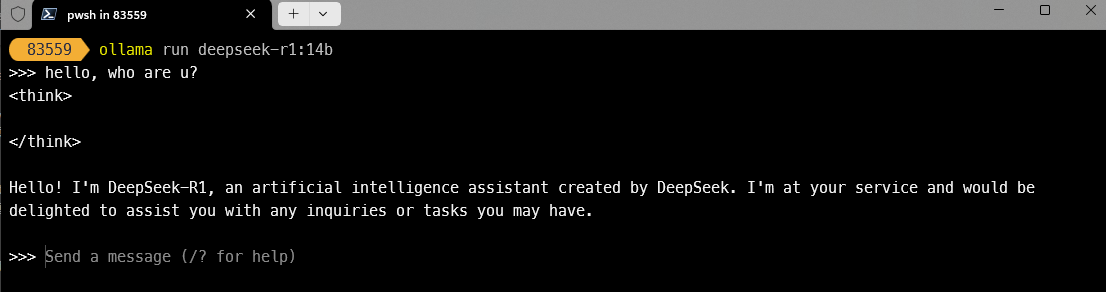
速度比预期快很多,4070S显卡能达到每秒 20个token 的生成速度,非常流畅。
但是本地部署的毕竟是蒸馏模型,有机会还是可以购买Deepseek的API,价格比之Openai的API优惠不知道多少(2025-02-07),满血模型的性能比蒸馏模型性能高好几个档次。
API调用
Ollama支持RESTful api调用,详见官方文档